Architecture of MyST and Curvenote Websites
On the importance of structured data
Franklin Koch, Rowan Cockett · January 22, 2023
This post discusses the architecture of MyST websites built with MyST CLI tools or Curvenote. In order to build a MyST site, you only need your content in MyST Markdown and Jupyter Notebooks. Navigate to a folder with these files and initialize a site with the MyST CLI or even deploy your content directly to the web with the Curvenote CLI.
Under the hood, when you build a website with MyST, source files are converted into structured JSON data, an abstract syntax tree (AST) which extends MDAST. This format is central to the flexibility of MyST tools; structured data is much easier to work with than file formats. From this AST, we can build PDFs, templated , Word documents, and, of course, interactive websites!

Figure 1:Markdown documents and Jupyter Notebooks are transformed into structured data. The structured data is served by a “content server” and accessed directly by a “theme server” to create a dynamic and interactive website, allowing you to switch out the theme on the fly!
The websites consist of two parts: (1) a content server, and (2) a theme server. The content server simply serves the structured JSON as well as site configuration data. The theme server does … well … whatever it wants!! This can be transforming the content into react components to build a simple, modern website. It can be writing static HTML from the content; this would be equivalent to a static site generator. It also opens the door to running a compute kernel and having a dynamic, interactive theme where computational content from the content server can be explored.
Why are MyST sites architected this way? Structured content is at the heart of open-science, to allow content to be Findable, Accessible, Interoperable, and Reusable — or just plain FAIR. The separation of concerns between the content being served and how it is presented also allows us to think about these problems independently, you can make your journal theme better, without having to re-render all of the articles, making this much less risky, you can experiment with ideas, and you can move faster!
At Curvenote, we are driven by making it easier for scientists to do their work and get it in front of your peers. You should not need to be concerned with the toil of formatting, publishing, etc. — it should just work! You should be able to work in familiar formats like Jupyter Notebooks and Markdown, then with minimal effort get that work in front of others to reproduce, interact, and collaborate on. 🎉
If you are using the Curvenote CLI, sharing can be done in 7 seconds with:
curvenote deploy
See a webinar or a 3 minute demo 🚀
Content & Theme Servers¶
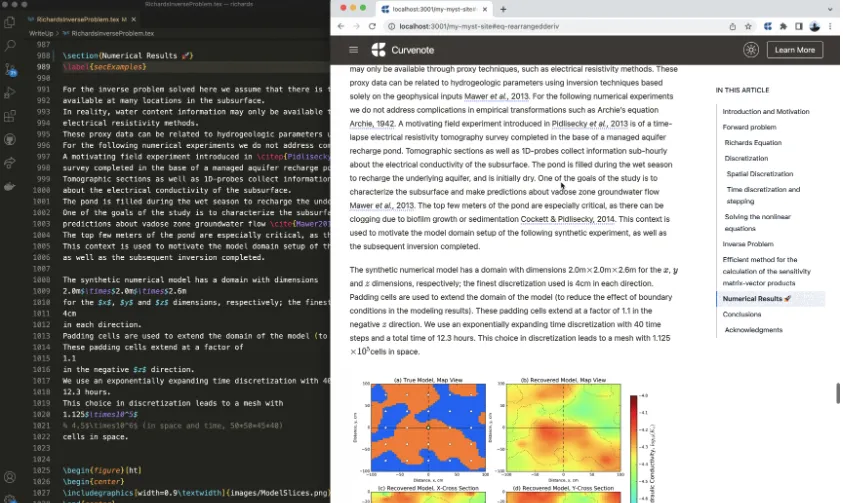
Our first concern with the content server is pulling as much as possible out of the source documents into structured data; we should be able to do this without caring at all about what we will subsequently build (a PDF, a static site, a rich interactive site, a visualization, an app). Then, we want to build (or let other people build) themes to display and interact with this content, entirely independent of the content itself. This approach is philosophically similar to Jamstack, where the core of the site content is entirely static but “Javascript” (i.e. the J in JAM) can be added on top for dynamic interactivity.
The separation between content server data and theme server data is also apparent in the folder structure. At the root level lives the content created directly by the user. In the _build folder, the content generated by MyST is isolated in a subfolder called site. This is served as is, usually on port 3100, if you want to explore this server directly, run myst start --headless, which will just start the content server and tell you about it outside of the debug logs!

Figure 2:Major components of the content and theme servers. The content server exposes a config.json, structured content for each page, and all of the linked images and original files. The theme is composed of some sort of server/framework (we love @remix-run!). The theme can also reuse components, such as myst-to-react and also exposes all template options in a data-driven template.yml.
The theme server is cloned to a separate subfolder under _build in the templates directory! An example theme is the Curvenote book theme, every theme should expose a template.yml in the root of the repository, which exposes options like logo or analytics_google in this case.
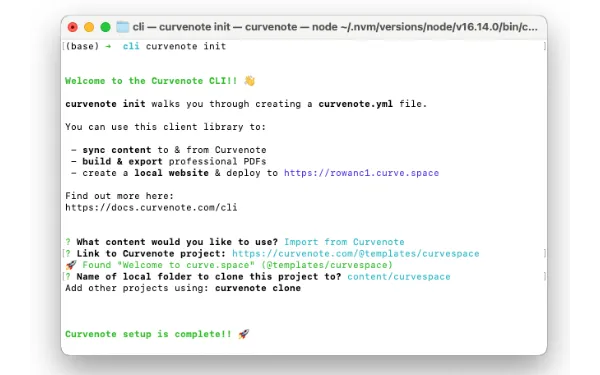
If your theme is packaged as a myst-template (see contributing docs), you can see details about it using the myst templates command:
myst templates list book-theme --site
Figure 3:Output of the myst templates list book-theme --site command.
The theme server also should determine commands for installing and starting the server, these will be run by the MyST CLI. In the case of the book-theme this is done with npm install and npm run start, but will be different if you choose to build your theme in Python, or some other language!
Structured Data¶
At Curvenote, we are big believers in creating and exposing structured data for scientific and technical communication. The choices that we have made in architecting the MyST website allows for novel themes for reading and interacting with scientific content that can pull on the latest technologies. For example, imagine being able to pull in a reference to a scientific figure — that is fully interactive and comes with compute and data accessible.
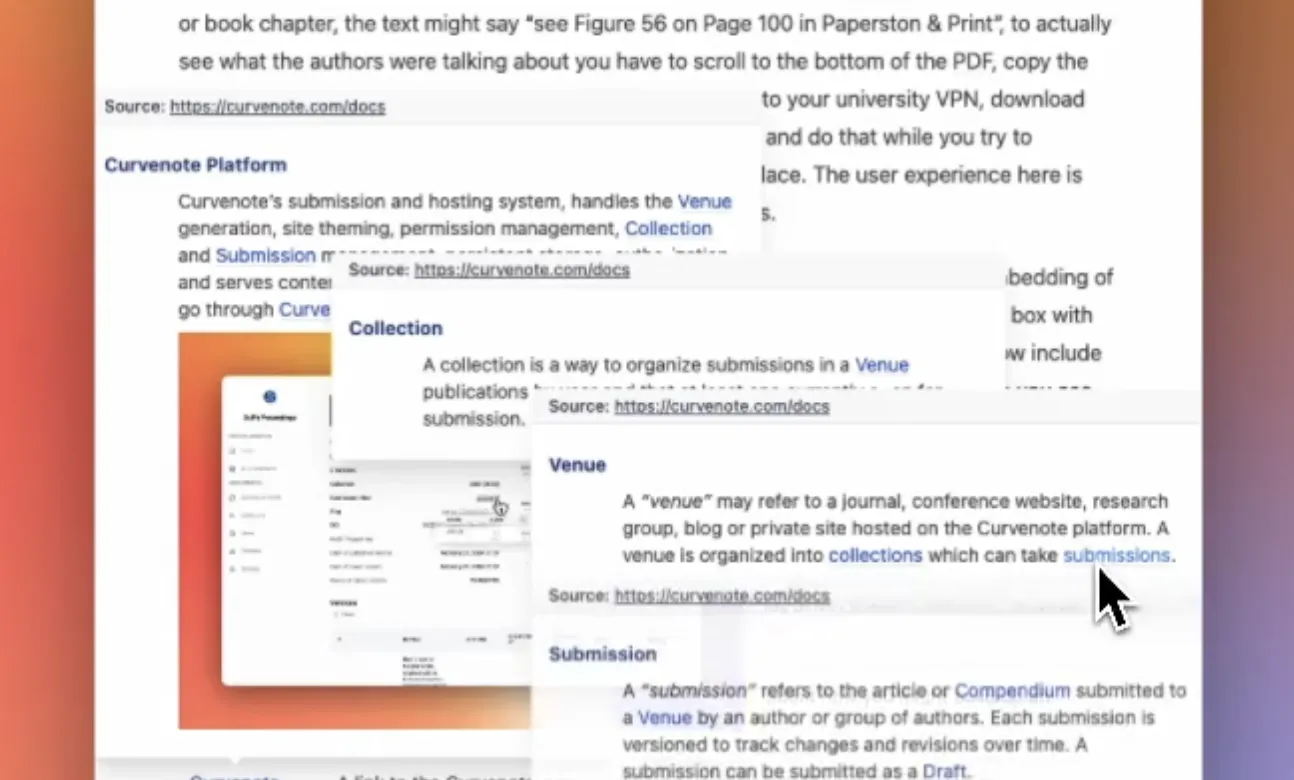
Figure 4:Clicking on a reference to content in a different myst project can instantly show you a preview of the figure, equation, or paragraph. This is only possible if you expose your content as structured data!
Try MyST or the Curvenote CLI¶
To get started with these ideas, start with the MyST CLI, which has a MyST quickstart guide, which will walk you through installing myst, and creating scientific PDFs or websites, blogs and journals.
If you are involved in publishing, journals or just want a kick-ass lab-group website, we would love to show you a demo.