How to use LaTeX with MyST Markdown
Rowan Cockett · January 7, 2023
Curvenote is currently working with multiple journals who are submitting their manuscripts in , and Jupyter Notebooks and we have needed a way to convert and render the articles online as well as capture the structured data in JATS XML. Our philosophy is that the author should remain in control of the writing experience all the way through the publication process so that any changes are made in the original format(s). This means we need robust ways to parse documents, and over the past few months we have developed this process using MyST Markdown.
The MyST Tools project, https://mystmd.org, includes a command line interface for creating websites, scientific articles, and parsing markdown, notebooks, JATS, and now also can parse and render directly! 🎉
Working with in MyST¶
To get started with rendering a document using MyST, install the CLI and navigate to a folder with your *.tex documents and type myst init and then myst start[1]. This will bring up a dynamic web-server that will render your article, with near real-time parsing (~300ms for one of my scientific papers), and solid error-reporting for any unknown macros or parsing errors (like unknown cross-references or math rendering issues). The experience can be seen as in Figure 1, with the MyST website having interactive hover-cross-references, and almost live-updates as you type and save your document.
Figure 1:Parsing and rendering in MyST as an interactive website.
Pulling out Frontmatter¶
Currently our parser adds some additional logic for pulling out author, title and affiliation information and providing that in a more standardized form (i.e. myst-frontmatter). This allows us to create professional and data-rich information for the journals that Curvenote works with. For example, an example of Crystal Orientation Mapping automatically pulls out the information from the document and captures that information in machine-readable formats (JSON and JATS!).

Figure 2:An example of a journal-template that parses rich frontmatter out of a document.
Error Messages & Partial Renderings¶
One of the things that makes very hard to use are the confusing error and warning messages. For example, phrases like “badness 10000” and the extreme verbosity of the logs means key information is lost.
Sorry, but I’m not programmed to handle this case; I’ll just pretend that you didn’t ask for it.
Your friendly, conversational Compiler
One of the things that I really like about MyST is that it gives specific and actionable error messages. For example, Figure 3 is a rendering of an article with warnings. Some of the warnings are about using math, the warnings are created to be actionable (i.e. that have enough information about what should be improved with links to other sources), and specific — there is a line number and column number of the exact location of the issue. If you are using a tool like VSCode, you can actually click on those error messages and the editor will open to the exact location of the warning.

Figure 3:Error messages and warnings are specific and actionable using MyST.
When an error is encountered, the parser does its best to recover and show a partial rendering. For example, with incorrect math, missing images or citations, these are shown with the errors in your web-browser preview. In the future we will probably hook up the full loop here so that you can jump back and forth between you input text and rendered results — even now though, I find this extremely helpful when authoring in , especially because the feedback loop to rendering is about ⚡️ 16 times faster ⚡️ than the current renderer I am using (xelatex).

Figure 4:Partial rendering of errors in MyST.
We have also put a lot of work into making sure that the most important information is available when you are looking through the CLI messages, including dimming notes or follow up information and using color to differentiate errors and warnings. These are table-stakes features in CLIs that are built today, but the upgrade from ’s log messages is very noticeable, and I have started finding small bugs that I never would have discovered otherwise (e.g. repeated packages or macros).
How it Works¶
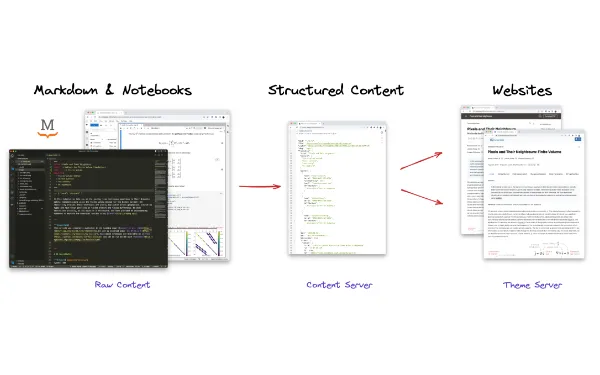
MyST is a stand-alone parser and renderer. We started this process to access the frontmatter (title, abstract, authors, affiliations, emails, ORCIDs, etc.) in a document — but the library that we used for parsing got us much further to a full solution than we expected.
The @unified-latex libraries are currently used for tokenizing the *.tex files, including rich information about source-code positions which are used in the error messages. This token stream has some information about basic commands, but is primarily focused on the structure of the markup — arguments, brackets, nesting, whitespace. The parse step uses tex-to-myst to convert this token stream into a myst-spec abstract syntax tree (AST). This is well documented (https://myst-transforms library is used to add rich information about cross-references, and all of the error messages about math, missing citations, etc. All of the transforms are common infrastructure across the entire MyST ecosystem, and can be used independently (see docs). Finally the document is rendered using in this case myst-to-react, which allows rich interactivity for websites.

Figure 5:The process of parsing and rendering with MyST.
The rendering is done on a watch process, with efficient caching of partial resources and file-system access — and from a user perspective all you have to remember is myst start.
⚡️ Speed ⚡️¶
The entire rendering process can run in a few hundred milliseconds from start to finish rather than around 3-10 seconds for small documents using common renderers. The paper I was testing on during this blog post is ⚡️ 16 times faster ⚡️ - which is significant, and there is lots of room for improvement in MyST as well!
Similar to many of the operations are cached so when running interactively, subsequent renders can be even faster (unlike we keep your working directory clean, with no random .bbl, .aux, and .fls files hanging around). The speed of rendering means instant previews and fast feedback to what you are writing. There is a lot that we can still optimize, but at the current speed this isn’t the bottleneck!
Written entirely in JavaScript¶
Importantly, it is also completely written in JavaScript[2], which means that this parser and renderer can run completely client-side. I think this will open up many other possibilities in the future for editing applications.
The Long Tail of ¶
There is a very, very, very long tail of things that can be done in , and many of those libraries and conventions may not even be appropriate for a web-first presentation (e.g. page-numbers, absolute positioning of figures, etc.). The current parser works really well for scientific articles, not currently presentations or posters, and is probably missing a favorite feature of yours (it is only 4 weeks old! 🐣). We will continue to add features and fix bugs — especially for the journal submissions that we are working with. There are also some features that need to get further developed in MyST (e.g. improved support for subfigures and sub-equations).
There are some features that we won’t ever implement in Javascript (e.g. tikz), however, we can still support these figures through pulling out the various sections and using a PDF renderer to create a figure that can then be used in-place. This could all be done transparently, or use a web-service if client-side.
Alternatives¶
There are a lot of different ways to work with out there. In keeping with the standards in the scientific Python ecosystem we are looking for MIT / BSD licensed libraries (or permissive equivalents), for example, see this post from the early days on advocating for BSD licensing across the ecosystem that many credit with the growth of Python. We also want programs that can run entirely in a browser, as these have the potential to be used and incorporated in many different communities and workflows. Without these requirements, there are a lot of other options to look at, for example, Pandoc[3] or Quarto[4]. Pandoc may soon be able to be used in the browser, but is likely going to be slower[5]. Another option is to look closer at the latexml package (Ginev et al. (2011)), which is used in the ar5iv renderings of arXiv documents and has MUCH more comprehensive support. A path to using that library may be to focus on JATS as the intermediate exchange format, and then parse that with the jats-to-myst library.
There are probably also many other libraries or approaches, let us know on social[6]:
🐘 or 🦋.
Getting started with web-native ¶
If you are looking to create a website from your documents, or just looking to keep up with the MyST development, give the latest version (v0.1.5) a try, and raise some issues to help us expand support!