Embracing Reuse in Scientific Communication
Introducing MyST based tools for easily reusing scientific content
rowan - Executable Books · May 11, 2024
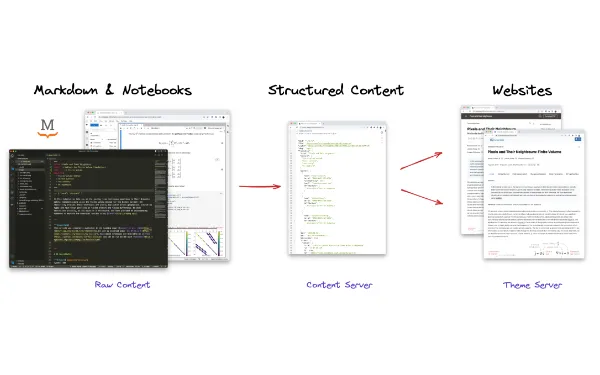
Scientific publishing today uses outdated technology for communicating and sharing knowledge, relying on PDFs, static figures, and text-only references that are a poor representation of the complexity of the science and data. This gap slows the speed of research dissemination, reuse, and uptake and completely impedes “networked knowledge” and importing/reusing work in a structured way. For example, “importing” visualizations, equations or any other deeply-linked content – including provenance information – into new research articles, documentation or educational sites is completely impossible in today’s research ecosystem. As a metaphor, compare open-access science to open-source programming: it would be a world without package managers to share, version, reuse and rapidly build upon other peoples work in a structured way. The open-source ecosystem would not exist without this infrastructure.
Effective and practical reuse of content that maintains attribution, provenance, and links to software and data is fundamental infrastructure that does not exist at scale in science.
Open infrastructure for communicating science also has to be easy to integrate into existing tools, support computational, interactive components, be archivable for the long term, and be adopted by our existing sociotechnical system of societies, journals, and institutions. There are two interconnected problems that need to be solved: (1) upgrade existing scientific authoring tools, ensuring these are integrated into both scientific and data-science ecosystems; and (2) develop radically better ways to share content as individuals, small groups, preprints, and formalized, traditional journals with existing societies and institutions. The two problems are connected, in that the authoring tools should be able to deeply integrate with new publishing mediums (e.g. referencing a figure from a publication should be able to show you that figure directly as you are authoring, including all interactivity and computation).
Interactive References¶
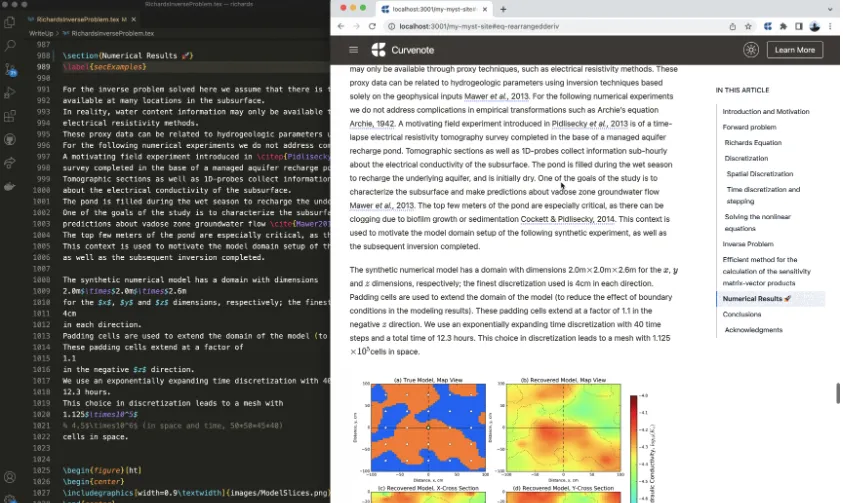
Think how you interact with scientific references today: when referencing a figure in a paper or book chapter, the text might say “see Figure 56 on Page 100 in Paperston & Print”, to actually see what the authors were talking about you have to scroll to the bottom of the PDF, copy the reference, paste it into Google, get stuck at a paywall, log into your university VPN, download the PDF, open it in Zotero, scroll to page 100, find figure 56, and do that while you try to remember if it was worth the effort to look it up in the first place. The user experience here is terrible, and is wasting valuable time for millions of scientists.
Today Curvenote is launching a comprehensive workflow for referencing and embedding of scientific content, which we have helped to build directly into the community-based MyST Markdown tools (https://mystmd.org). This works out of the box with Curvenote’s publishing platform. In the xref:docsxref: syntax that many of the ExecutableBooks team has contributed to.
Table 1:Examples of hover references to instantly access open-science content.
Reference | Why this is so cool |
|---|---|
External figure from Heagy & Oldenburg, 2024. This is on Lindsey’s lab group website that is hosted by Curvenote. | |
External equation from that same resource, think about how you might build up an equation bank?! | |
A link to the Curvenote documentation that has a list of product terminology, an excellent way to share and curate technical information for your community, product or discipline. | |
xref:docs |
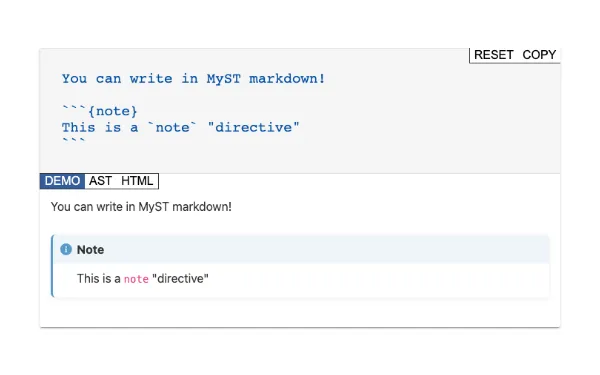
☝️ Try hovering over one of the cross references above. If will bring you to the source of the content and show it directly in context.
Figure 1:Interact with Table 1 above and you can see how cross-references to external sites work for images, equations, sections, terms, and xref:docs
Use Cases in Education¶
Lindsey Heagy, a scientific advisor of Curvenote, gave a practical talk on how to organize content at Scipy 2016; it is a video I re-watch every few months. Lindsey describes a metaphor of comparing open-science to open-source programming and the sorts of infrastructures and practices that are in place to enable reuse at scale. These analogies are illustrative for science to radically improve reuse of content in education and research communication; reuse is something that drives all of the FAIR data principles. The ability to reuse content is directly tied to the effort that is put into improving a resource; for example, if a resource is a one off that isn’t reused the value of improving, structuring and organizing content is often limited. With reuse at a core design goal, we can enable iteration in place, which promotes investing in structure, rigour, metadata, and reproducibility.
Figure 2:Lindsey and I have been exploring and working on these ideas on how to refactor and explore knowledge. Lindsey Heagy gave a fantastic SciPy talk in 2016 that laid out general ideas on how to improve the reuse of knowledge by making an analogy to open-source software. It is exciting that this year Curvenote is sponsoring the SciPy Proceedings and bringing those ideas to the whole scientific python community.
Embedding Open Content¶
Our goal at Curvenote, and why we are investing heavily in the xref:docs
We see a lot of potential in educational content, where you can embed glossary terms, equations and content across community resources. Here is an example of embedding from Curvenote’s product glossary, all of the hover-references and links continue to work!
There is still a lot of work to understand the best patterns around the user experience, and ensuring that the embedded content is distinct and shows the licensing and attribution if that is the goal of the author. These are exciting questions that these features enable us to ask and unlock the potential of working with and reusing structured data.
To learn more about MyST Markdown, see the documentation on references and embedding. To start a journal, preprint server, or lab-group website contact Curvenote for a demo.